摘要
最近的工作表明,如果卷积网络在靠近输入的层与靠近输出的层之间包含更短的连接,那么卷积网络的深度可以显著增加,准确度更高,并且更易于训练。在本文中,我们采纳这一观点,并提出了密集连接卷积网络(DenseNet),它以前馈的方式将每个层与每个其它层连接起来。具有L层的传统卷积网络具有L个连接(每个层与其后续层之间),而我们的网络具有的连接个数为:$\frac{L(L+1)}{2}$。对于每个层,所有先前层的特征图都被用作本层的输入,并且本层输出的特征图被用作所有后续层的输入。DenseNet有几个优点:它们可以减轻梯度弥散问题,加强特征传播,鼓励特征重用,大大减少参数数量。我们在四个竞争激烈的对象识别基准任务(CIFAR-10, CIFAR-100, SVHN, ImageNet)上对我们提出的网络架构进行评估。相较于其它最先进的方法,DenseNet在大多数情况下都有显著的改善,同时要求较少的算力以实现高性能。代码和预训练的模型可以在https://github.com/liuzhuang13/DenseNet上找到。
简介
各种卷积神经网络(CNN)已经成为视觉对象识别的主要机器学习方法。虽然它们最早是在20多年前被提出的1,但是直到近年来,随着计算机硬件和网络结构的改进,才使得训练真正深层的CNN成为可能。最早的LeNet52由5层组成,VGG有19层3,去年的Highway Network4和残差网络(ResNet)5已经超过了100层。
随着CNN越来越深,出现了一个新的研究问题:梯度弥散。许多最近的研究致力于解决这个问题或相关的问题。ResNet5和Highway Network4通过恒等连接将信号从一个层传递到另一层。Stochastic depth6通过在训练期间随机丢弃层来缩短ResNets,以获得更好的信息和梯度流。FractalNet7重复地将几个并行层序列与不同数量的约束块组合,以获得大的标称深度,同时在网络中保持许多短路径。虽然这些不同的方法在网络拓扑和训练过程中有所不同,但它们都具有一个关键特性:它们创建从靠近输入的层与靠近输出的层的短路径。
在本文中,我们提出了一种将这种关键特性简化为简单连接模式的架构:为了确保网络中各层之间的最大信息流,我们将所有层(匹配的特征图大小)直接连接在一起。为了保持前馈性质,每个层从所有先前层中获得额外的输入,并将其自身的特征图传递给所有后续层。如下图(图1)所示:(5层的密集连接块,增长率$k=4$,每一层都把先前层的输出作为输入)
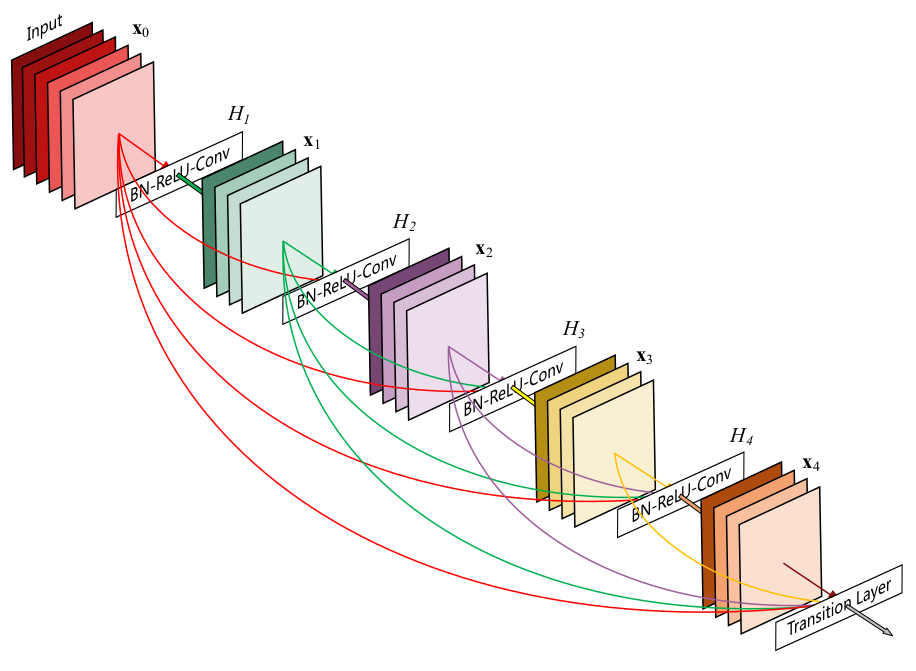
最重要的是,与ResNet相比,我们从不将特征通过求和合并后作为一层的输入,我们将特征串联成一个更长的特征。因此,第$\ell$层有$\ell$个输入,由所有先前卷积块的特征图组成。它自己的特征图传递给所有$L-\ell$个后续层。这样,在L层网络中,有$\frac{L(L+1)}{2}$个连接,而不是传统架构中仅仅有$L$个连接。由于其密集的连接模式,我们将我们的方法称为密集连接卷积网络(DenseNet)。
这种密集连接模式的可能的反直觉效应是,它比传统卷积网络需要的参数少,因为不需要重新学习冗余特征图。传统的前馈架构可以被看作是具有状态的算法,它是从一层传递到另一层的。每个层从上一层读取状态并写入后续层。它改变状态,但也传递需要保留的信息。 ResNet5通过加性恒等转换使此信息保持明确。 ResNet的最新变化6表明,许多层次贡献很小,实际上可以在训练过程中随机丢弃。这使得ResNet的状态类似于(展开的)循环神经网络(recurrent neural network)8,但是ResNet的参数数量太大,因为每个层都有自己的权重。我们提出的DenseNet架构明确区分添加到网络的信息和保留的信息。 DenseNet层非常窄(例如,每层12个卷积核),仅将一小组特征图添加到网络的“集体知识”,并保持剩余的特征图不变。最终分类器基于网络中的所有特征图。
除了更好的参数效率,DenseNet的一大优点是它改善了整个网络中信息流和梯度流,从而使其易于训练。每个层都可以直接从损失函数和原始输入信号中获取梯度,从而进行了深入的监督9。这有助于训练更深层的网络架构。此外,我们还观察到密集连接具有正则化效应,这减少了具有较小训练集大小的任务的过拟合。
我们在四个高度竞争的基准数据集(CIFAR-10,CIFAR-100,SVHN和ImageNet)上评估DenseNet。在准确度相近的情况下,我们的模型往往需要比现有算法少得多的参数。此外,我们的模型在大多数测试任务中,准确度明显优于其它最先进的方法。
相关工作
网络架构的探索一直是神经网络研究的一部分。最近神经网络流行的复苏也使得这个研究领域得以恢复。现代网络中越来越多的层扩大了架构之间的差异,激发了对不同连接模式的探索和对旧的研究思想的重新审视。
类似于我们提出的密集网络布局的级联结构已经在20世纪80年代的神经网络文献中被研究10。他们的开创性工作着重于以逐层方式训练的全连接多层感知机。最近,用批量梯度下降训练的全连接的级联网络的方法被提出11。虽然对小数据集有效,但这种方法只能扩展到几百个参数的网络。在12 13 14 15中,通过跳连接在CNN中利用多层次特征已被发现对于各种视觉任务是有效的。与我们的工作同时进行的,16为具有类似于我们的跨层连接的网络衍生了一个纯粹的理论框架。
Highway Network4是其中第一个提供了有效训练100多层的端对端网络的方案。使用旁路与门控单元,可以无困难地优化具有数百层深度的Highway Network。旁路是使这些非常深的网络训练变得简单的关键因素。 ResNet5进一步支持这一点,其中纯恒等映射用作旁路。 ResNet已经在许多挑战性的图像识别,定位和检测任务(如ImageNet和COCO对象检测)上取得了显著的创纪录的表现5。最近,Stochastic depth被提出作为一种成功地训练1202层ResNet的方式6。Stochastic depth通过在训练期间随机丢弃层来改善深层ResNet的训练。这表明不是所有的层都是有必要存在的,并且突显了在深层网络中存在大量的冗余。本文一定程度上受到了这一观点的启发。具有预激活的ResNet还有助于对具有超过1000层的最先进网络的训练17。
另一种使网络更深的方法(例如,借助于跳连接)是增加网络宽度。 GoogLeNet18 19使用一个“Inception模块”,它连接由不同大小的卷积核产生的特征图。在20中,提出了具有宽广残差块的ResNet变体。事实上,只要深度足够,简单地增加每层ResNets中的卷积核数量就可以提高其性能21。FractalNet也可以使用更宽的网络结构在几个数据集上达到不错的效果7。
DenseNet不是通过更深或更宽的架构来获取更强的表示学习能力,而是通过特征重用来发掘网络的潜力,产生易于训练和高效利用参数的浓缩模型。由不同层次学习的串联的特征图增加了后续层输入的变化并提高效率。这是DenseNet和ResNet之间的主要区别。与Inception网络18 19相比,它也连接不同层的特征,DenseNet更简单和更高效。
还有其他显著的网络架构创新产生了有竞争力的效果。网中网(NIN)22的结构包括将微多层感知机插入到卷积层的卷积核中,以提取更复杂的特征。在深度监督网络(DSN)9中,隐藏层由辅助分类器直接监督,可以加强先前层次接收的梯度。梯形网络23 24引入横向连接到自动编码器,在半监督学习任务上产生了令人印象深刻的准确性。在25中,提出了通过组合不同基网络的中间层来提高信息流的深度融合网络(DFN)。通过增加最小化重建损失路径的网络也使得图像分类模型得到改善26。
DenseNet
考虑在一个卷积网络中传递的单独图像$x_{0}$。这个网络包含$L$层,每层都实现了一个非线性变换$H_{\ell}(\cdot)$,其中$\ell$表示层的索引。$H_{\ell}(\cdot)$可以是诸如批量归一化(BN)27、线性整流单元(ReLU)28、池化(Pooling)2或卷积(Conv)等操作的复合函数。我们将第$\ell$层输出表示为$x_{\ell}$。
ResNet:传统的前馈卷积神经网络将第$\ell$层的输出作为第$\ell+1$层的输入,可表示为:$x_{\ell} = H_{\ell}(x_{\ell-1})$。ResNet添加了一个跳连接,即使用恒等函数跳过非线性变换: \(x_{\ell} = H_{\ell}(x_{\ell-1}) + x_{\ell-1} \tag{1}\)
ResNets的一个优点是梯度可以通过从后续层到先前层的恒等函数直接流动。然而,恒等函数与$H_{\ell}$的输出是通过求和组合,这可能阻碍网络中的信息流。
密集连接:为了进一步改善层之间的信息流,我们提出了不同的连接模式:我们提出从任何层到所有后续层的直接连接。因此,第$\ell$层接收所有先前图层的特征图,$x_{0},…,x_{\ell-1}$,作为输入: \(x_{\ell} = H_{\ell}([x_{0},x_{1},...,x_{\ell-1}]) \tag{2}\) 其中$[x_{0},x_{1},…,x_{\ell-1}]$表示$0,…,\ell-1$层输出的特征图的串联。由于其密集的连接,我们将此网络架构称为密集卷积网络(DenseNet)。为了便于实现,我们将公式$(2)$中的$H_{\ell}(\cdot)$的多个输入连接起来变为单张量。
复合函数:受到17的启发,我们将$H_{\ell}(\cdot)$定义为进行三个连续运算的复合函数:先批量归一化(BN)27,然后是线性整流单元(ReLU)28,最后接一个$3\times3$的卷积(Conv)。
池化层:当特征图的大小变化时,公式$(2)$中的级串联运算是不可行的。所以,卷积网络的一个必要的部分是改变特征图尺寸的下采样层。为了便于我们的架构进行下采样,我们将网络分为多个密集连接的密集块,如下图(图2)所示:(一个有三个密集块的DenseNet。两个相邻块之间的层被称为过渡层,并通过卷积和池化来改变特征图大小。)

我们将块之间的层称为过渡层,它们进行卷积和池化。我们实验中使用的过渡层由一个批量归一化层(BN),一个$1\times1$的卷积层和一个$2\times2$平均池化层组成。
增长率:如果每个$H_{\ell}$函数输出$k$个特征图,那么第$\ell$层有$k_{0} + k \times (\ell - 1)$个输入特征图,其中$k_{0}$是输入层的通道数。与其它网络架构的一个重要的区别是,DenseNet可以有非常窄的层,比如$k = 12$。我们将超参数$k$称为网络的增长率。在实验这一节中可以看到,一个相对小的增长率已经足矣在我们测试的数据集上达到领先的结果。对此的一个解释是,每个层都可以访问其块中的所有先前的特征图,即访问网络的“集体知识”。可以将特征图视为网络的全局状态。每个层都将自己的$k$个特征图添加到这个状态。增长率调节每层对全局状态贡献多少新信息。与传统的网络架构不同的是,一旦写入,从网络内的任何地方都可以访问全局状态,无需逐层复制。
瓶颈层:尽管每层只产生$k$个输出特征图,但它通常具有更多的输入。在19 5中提到,一个$1\times1$的卷积层可以被看作是瓶颈层,放在一个$3\times3$的卷积层之前可以起到减少输入数量的作用,以提高计算效率。我们发现这种设计对DenseNet尤其有效,我们的网络也有这样的瓶颈层,比如另一个名为DenseNet-B版本的$H_{\ell}$是这样的:BN-ReLU-Conv($1\times1$)-BN-ReLU-Conv($3\times3$),在我们的实验中,我们让$1\times1$的卷积层输出$4k$个特征图。
压缩:为了进一步提高模型的紧凑性,我们可以在过渡层减少特征图的数量。如果密集块包含$m$个特征图,我们让后续的过渡层输出$\lfloor\theta m \rfloor$个特征图,其中$\theta$为压缩因子,且$0 < \theta \le 1$。当$\theta = 1$时,通过过渡层的特征图的数量保持不变。我们将$\theta < 1$的DenseNet称作DenseNet-C,我们在实验设置$\theta = 0.5$。我们将同时使用瓶颈层和压缩的模型称为DenseNet-BC。
实现细节:在除ImageNet之外的所有数据集上,我们实验中使用的DenseNet具有三个密集块,每个具有相等层数。在进入第一个密集块之前,对输入图像执行卷积,输出16(DenseNet-BC的增长率的两倍)通道的特征图。对于卷积核为$3\times3$的卷积层,输入的每一边都添加1像素宽度的边,以0填充,以保持特征图尺寸不变。在两个连续的密集块之间,我们使用一个$1\times1$的卷积层接一个$2\times2$的平均池化层作为过渡层。在最后一个密集块的后面,执行全局平均池化,然后附加一个softmax分类器。三个密集块的特征图尺寸分别是$32\times32$,$16\times16$和$8\times8$。在实验中,基础版本的DenseNet超参数配置为:${ L = 40, k = 12 }$,${ L = 100, k = 12 }$和${ L = 100, k = 24 }$。DenseNet-BC的超参数配置为:${ L = 100, k = 12 }$,${ L = 250, k = 24 }$和${ L = 190, k = 40 }$。
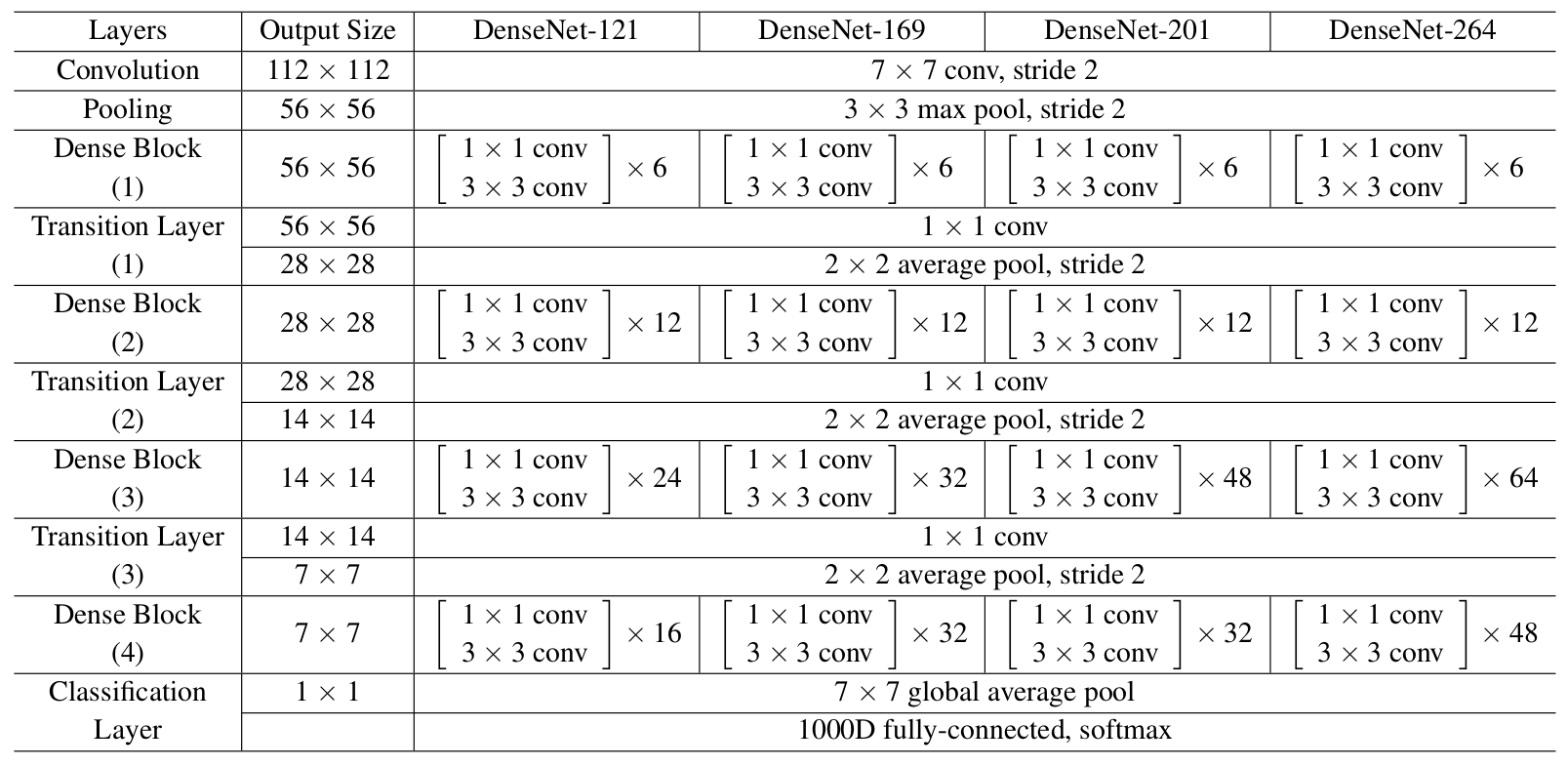
在ImageNet上的实验,我们使用的DenseNet-BC架构包含4个密集块,输入图像大小为$224\times224$。初始卷积层包含$2k$个大小为$7\times7$,步长为2的卷积。其它层的特征图数量都由超参数$k$决定。具体的网络架构如下表(表1)所示:(用于ImageNet的DenseNet网络架构。所有网络的增长率都是$k = 32$。注意,表格中的Conv层表示BN-ReLU-Conv的组合)
实验
我们经验性地证明了DenseNet在几个基准数据集上的有效性,并与最先进的架构进行比较,特别是ResNet及其变体。
数据集
CIFAR:两个CIFAR数据集都是由$32\times32$像素的彩色照片组成的。CIFAR-10(C10)包含10个类别,CIFAR-100(C100)包含100个类别。训练和测试集分别包含50,000和10,000张照片,我们将5000张训练照片作为验证集。我们采用广泛应用于这两个数据集的标准数据增强方案(镜像/移位)5 6 7 22 29 9 30 4。我们通过数据集名称末尾的“+”标记(例如,C10+)表示该数据增强方案。对于预处理,我们使用各通道的均值和标准偏差对数据进行归一化。对于最终的训练,我们使用所有50,000训练图像,作为最终的测试结果。
SVHN:街景数字(SVHN)数据集由$32\times32$像素的彩色数字照片组成。训练集有73,257张照片,测试集有26,032张照片,以及531,131张照片进行额外的训练。按照常规做法31 6 9 22 32,我们使用所有的训练数据,没有任何数据增强,使用训练集中的6,000张照片作为验证集。我们选择在训练期间具有最低验证错误的模型,作最终的测试。我们遵循21并将像素值除以255,使它们在$[0,1]$范围内。
ImageNet:ILSVRC 2012分类数据集33包含1000个类,训练集120万张照片,验证集50,000张照片。我们采用与34 5 17相同的数据增强方案来训练照片,并在测试时使用尺寸为$224\times224$的single-crop和10-crop。与5 17 6一样,我们报告验证集上的分类错误。
训练
所有网络都使用随机梯度下降(SGD)进行训练。在CIFAR和SVHN上,我们训练批量为64,分别训练300和40个周期。初始学习率设置为0.1,在训练周期数达到50%和75%时除以10。在ImageNet上,训练批量为256,训练90个周期。学习速率最初设置为0.1,并在训练周期数达到30和60时除以10。由于GPU内存限制,我们最大的模型(DenseNet-161)以小批量128进行训练。为了补偿较小的批量,我们训练该模型的周期数为100,并在训练周期数达到90时将学习率除以10。
根据34,我们使用的权重衰减为$10^{-4}$,Nesterov动量35为0.9且没有衰减。我们采用36中提出的权重初始化。对于没有数据增强的三个数据集,即C10,C100和SVHN,我们在每个卷积层之后(除第一个层之外)添加一个Dropout层37,并将Dropout率设置为0.2。只对每个任务和超参数设置评估一次测试误差。
CIFAR和SVHN上的分类结果
我们训练不同深度$L$和增长率$k$的DenseNet。 CIFAR和SVHN的主要结果如下表(表2)所示:(CIFAR和SVHN数据集的错误率(%)。 $k$表示网络的增长率。超越所有竞争方法的结果以粗体表示,整体最佳效果标记为蓝色。 “+”表示标准数据增强(翻转和/或镜像)。“*”表示我们的运行结果。没有数据增强(C10,C100,SVHN)的DenseNets测试都使用Dropout。使用比ResNet少的参数,DenseNets可以实现更低的错误率。没有数据增强,DenseNet的表现更好。)
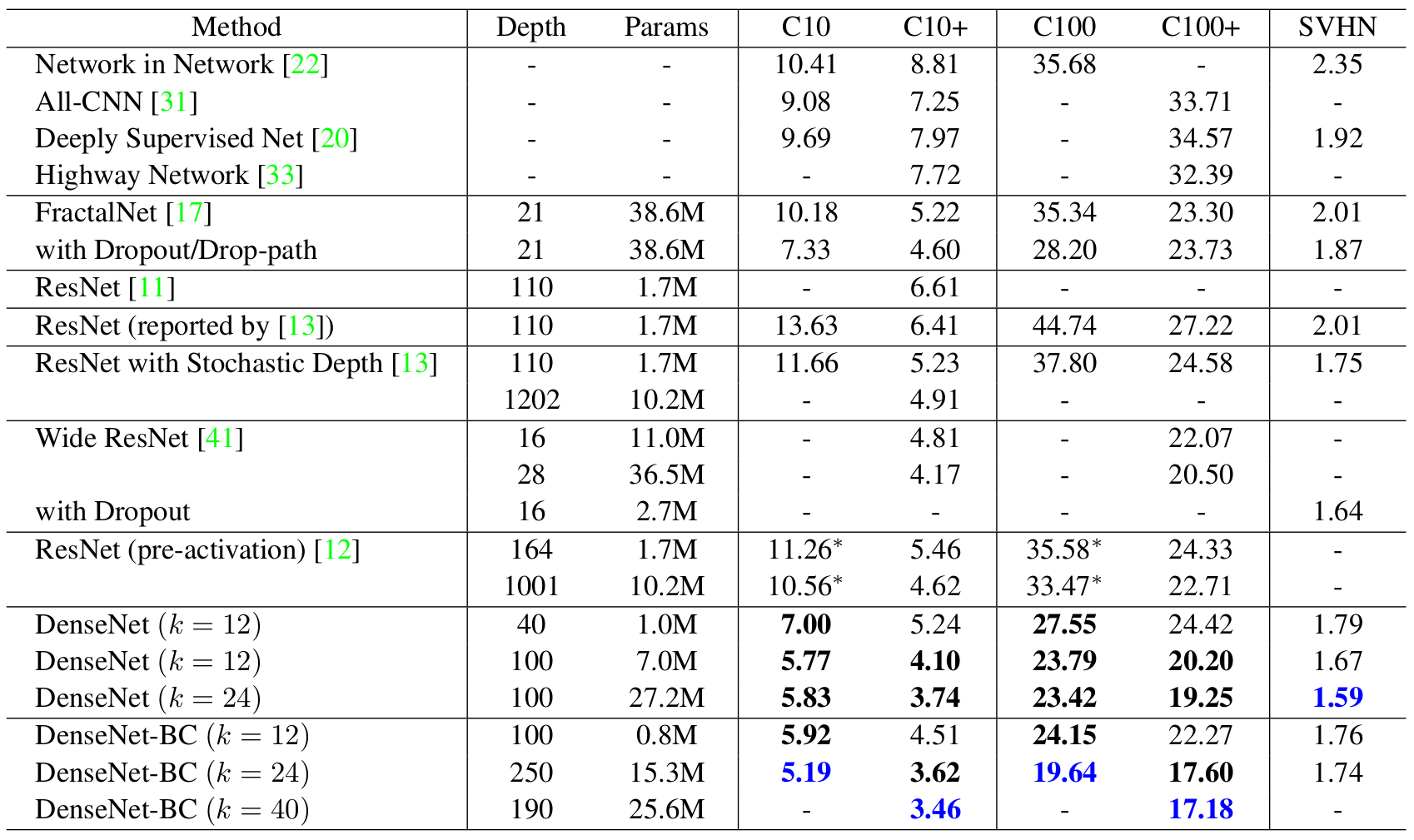
准确率:可能最明显的趋势在表2的底行,$L = 190$,$k = 40$的DenseNet-BC优于所有CIFAR数据集上现有的一流技术。它的C10+错误率为3.46%,C100+的错误率为17.18%,明显低于Wide ResNet架构的错误率21。我们在C10和C100(没有数据增强)上取得的最佳成绩更令人鼓舞:两者的错误率均比带有下降路径正则化7的FractalNet下降了接近30%。在SVHN上,在使用Dropout的情况下,$L = 100$,$k = 24$的DenseNet也超过Wide ResNet成为了当前的最佳结果。然而,相对于层数较少的版本,250层DenseNet-BC并没有进一步改善其性能。这可以解释为SVHN是一个相对容易的任务,极深的模型可能会过拟合训练集。
模型容量:在没有压缩或瓶颈层的情况下,总体趋势是DenseNet在$L$和$k$增加时表现更好。我们认为这主要是模型容量相应地增长。从表2中C10+和C100+列可以看出。在C10+上,随着参数数量从1.0M,增加到7.0M,再到27.2M,误差从5.24%,下降到4.10%,最终降至3.74%。在C100 +上,我们也可以观察到类似的趋势。这表明DenseNet可以利用更大更深的模型提高其表达学习能力。也表明它们不会受到类似ResNet那样的过度拟合或优化困难5的影响。
参数效率:表2中的结果表明,DenseNet比其它架构(特别是ResNet)更有效地利用参数。具有压缩和瓶颈层结构的DenseNet-BC参数效率最高。例如,我们的250层模型只有15.3M个参数,但它始终优于其他模型,如FractalNet和具有超过30M个参数的Wide ResNet。还需指出的是,与1001层的预激活ResNet相比,具有$L = 100$,$k = 12$的DenseNet-BC实现了相当的性能(例如,对于C10+,错误率分别为4.62%和4.51%,而对于C100+,错误率分别为22.71%和22.27%)但参数数量少90%。图4中右图显示了这两个网络在C10+上的训练误差和测试误差。 1001层深ResNet收敛到了更低的训练误差,但测试误差却相似。我们在下面更详细地分析这个效果。
过拟合:更有效地使用参数的一个好处是DenseNet不太容易过拟合。我们发现,在没有数据增强的数据集上,DenseNet相比其它架构的改善特别明显。在C10上,错误率从7.33%降至5.19%,相对降低了29%。在C100上,错误率从28.20%降至19.64%,相对降低约30%。在我们的实验中,我们观察到了潜在的过拟合:在C10上,通过将$k = 12$增加到$k = 24%使参数数量增长4倍,导致误差略微地从5.77%增加到5.83%。 DenseNet-BC的压缩和瓶颈层似乎是抑制这一趋势的有效方式。
ImageNet上的分类结果
我们在ImageNet分类任务上评估不同深度和增长率的DenseNet-BC,并将其与最先进的ResNet架构进行比较。为了确保两种架构之间的公平对比,我们采用Facebook34提供的ResNet的Torch实现来消除数据预处理和优化设置之间的所有其他因素的影响。我们只需将ResNet替换为DenseNet-BC,并保持所有实验设置与ResNet所使用的完全相同。
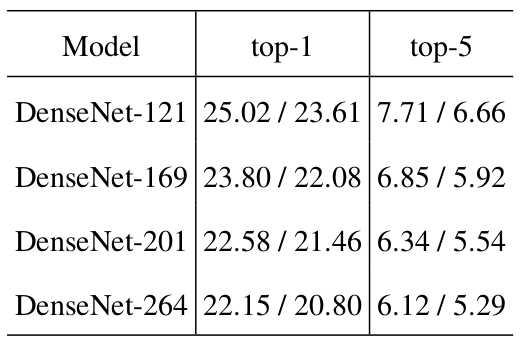
在ImageNet上DenseNets的测试结果如下表(表3)所示:(ImageNet验证集上的top-1和top-5错误率,测试分别使用了single-crop和10-crop)
将DenseNet和ResNet在验证集上使用single-crop进行测试,把top-1错误率作为参数数量(左)和计算量(右)的函数,结果如下图(图3)所示:
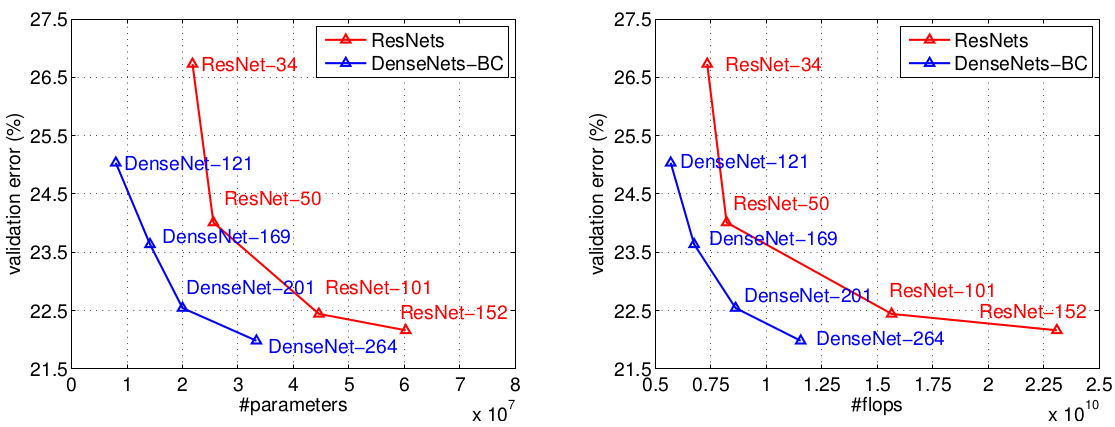
图中显示的结果表明,在DenseNet与最先进的ResNet验证误差相当的情况下,DensNet需要的参数数量和计算量明显减少。例如,具有20M个参数的DenseNet-201与具有超过40M个参数的101层ResNet验证误差接近。从右图可以看出类似的趋势,它将验证错误作为计算量的函数:DenseNet只需要与ResNet-50相当的计算量,就能达到与ResNet-101接近的验证误差,而ResNet-101需要2倍的计算量。
值得注意的是,我们的实验设置意味着我们使用针对ResNet优化的超参数设置,而不是针对DenseNet。可以想象,可以探索并找到更好的超参数设置以进一步提高DenseNet在ImageNet上的性能。(我们的DenseNet实现显存使用效率不高,暂时不能进行超过30M参数的实验。)
讨论
表面上,DenseNet与ResNet非常相似:公式$(2)$与公式$(1)$的区别仅仅是输入被串联而不是相加。然而,这种看似小的修改导致这两种网络架构产生本质上的不同。
模型紧凑性:作为输入串联的直接结果,任何DenseNet层学习的特征图可以由所有后续层访问。这有助于整个网络中的特征重用,并产生更紧凑的模型。
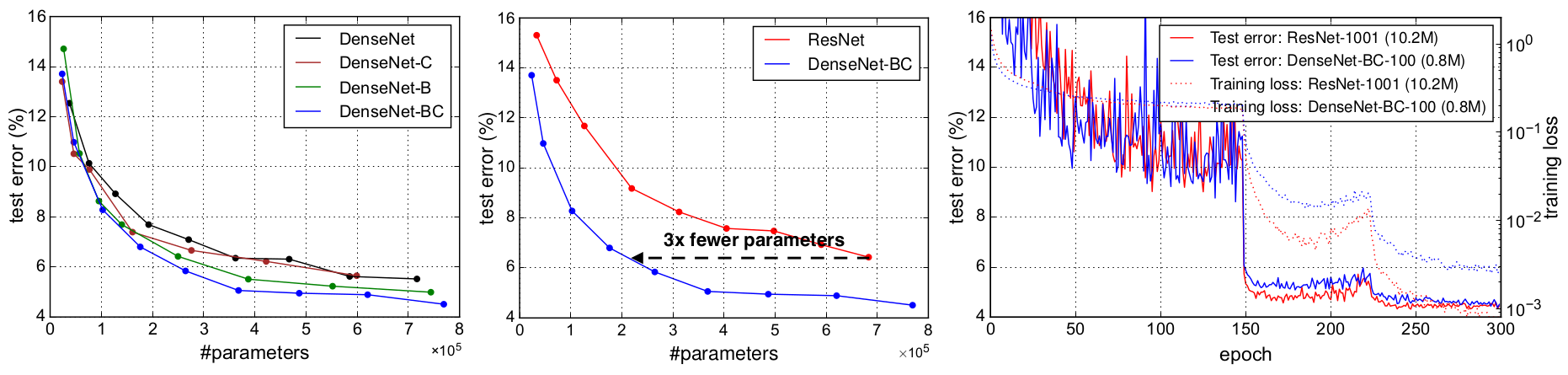
如上图(图4)所示,左边两个图显示了一个实验的结果,其目的是比较DenseNet(左)的所有变体的参数效率以及可比较的ResNet架构(中间)。我们对C10 +上的不同深度的多个小网络进行训练,并将其测试精度作为网络参数量的函数进行绘制。与其他流行的网络架构(如AlexNet 38或VGG3)相比,虽然具有预激活的ResNet使用更少的参数,但通常会获得更好的结果17。因此,我们将这个架构和DenseNet($k = 12$)进行比较。 DenseNet的训练设置与上一节保持一致。
图表显示,DenseNet-BC始终是DenseNet最具参数效率的变体。此外,为了达到相同的准确度,DenseNet-BC只需要ResNet参数数量的大约1/3(中间图)。这个结果与图3所示的ImageNet结果一致。图4中的右图显示,只有0.8M可训练参数的DenseNet-BC能够实现与1001层(预激活)ResNet相当的精度, ResNet 17具有10.2M参数。
隐性深度监督:密集卷积网络提高精度的一个可能的解释是,各层通过较短的连接从损失函数中接收额外的监督。可以认为DenseNet执行了一种“深度监督”。在深度监督的网络(DSN9)中显示了深度监督的好处,其中每个隐藏层都附有分类器,迫使中间层去学习不同的特征。
密集网络以一种简单的方式进行类似的深度监督:网络上的单一分类器通过最多两个或三个过渡层对所有层进行直接监督。然而,DenseNet的损失函数和形式显然不那么复杂,因为所有层之间共享相同的损失函数。
随机连接与确定连接:密集卷积网络与残差网络的随机深度正则化之间有一个有趣的联系6。在随机深度中,通过层之间的直接连接,残差网络中的层被随机丢弃。由于池化层不会被丢弃,网络会产生与DenseNet类似的连接模式:如果所有中间层都是随机丢弃的,那么在相同的池化层之间的任何两层直接连接的概率很小,尽管这些方法最终是完全不同的,但DenseNet对随机深度的解释可以为这种正规化的成功提供线索。
特征重用:通过设计,DenseNet允许层访问来自其所有先前层的特征映射(尽管有时通过过渡层)。我们进行实验,探查训练后的网络是否利用了这一特性。我们首先在C10+上,使用超参数:${ L = 40, k = 12 }$训练了一个DenseNet。对于任一块内的每个卷积层$\ell$,我们计算分配给与层$s$连接的平均(绝对)权重。如下图(图5)所示:(卷积层在训练后的DenseNet中的平均绝对卷积核权重。像素$(s, \ell)$表示在同一个密集块中,连接卷积层$s$与$\ell$的权重的平均$L1$范数(由输入特征图的数量归一化)。由黑色矩形突出显示的三列对应于两个过渡层和分类层。第一行表示的是连接到密集块的输入层的权重。)
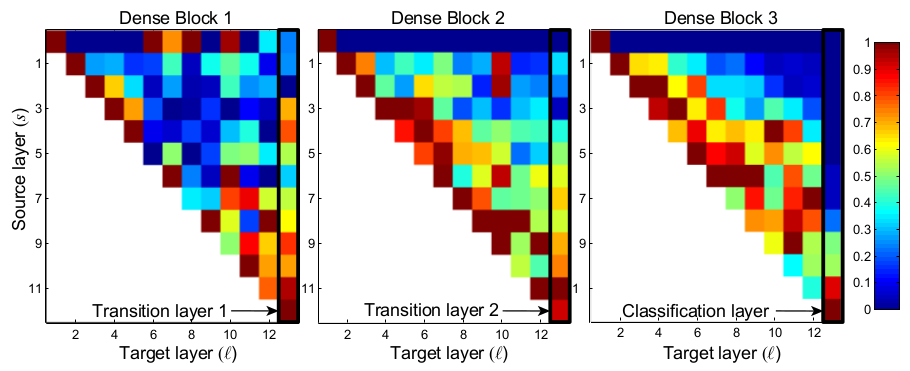
图5显示了所有三个密集块的热度图。平均绝对权重反映了层之间的依赖性。在坐标$(s, \ell)$上的红点表示层$\ell$高度依赖前$s$层生成的特征图。从图中可以看出:
- 任一层都在同一密集块内的许多输入上更新它们的权重。这表明,在同一密集块中,由先前层提取的特征实际上被后续层直接使用。
- 过渡层也在先前密集块内的所有层的输出上更新它的权重,这表明,信息从DenseNet的第一层到最后层进通过很少的间接传播。
- 第二和第三密集块内的层一致地将最小的权重分配给过渡层(三角形的顶行)的输出,表明过渡层输出许多冗余特征(平均权重较小) 。这与DenseNet-BC的强大结果保持一致,其中这些输出被压缩。
- 虽然最右边的分类层也在整个密集块中使用权重,但似乎集中在最终的特征图上,这表明最终的特征图中可能会出现更多的高级特征。
结论
我们提出了一个新的卷积网络架构,我们称之为密集卷积网络(DenseNet)。它引入了具有相同特征图大小的任意两个层之间的直接连接。我们发现,DenseNet可以轻易地扩展到数百层,而没有优化困难。在我们的实验中,DenseNet趋向于在不断增加的参数数量上提高准确性,没有任何性能下降或过度拟合的迹象。在多种不同的超参数设置下,在多个竞争激烈的数据集上获得了领先的结果。此外,DenseNet需要更少的参数和更少的计算来达到领先的性能。因为我们在研究中采用了针对残差网络优化的超参数设置,我们认为,通过更详细地调整超参数和学习速率表,可以获得DenseNet的精度进一步提高。
虽然遵循简单的连接规则,DenseNet自然地整合了恒等映射,深度监督和多样化深度的属性。它们允许在整个网络中进行特征重用,从而可以学习更紧凑的,并且根据我们的实验,更准确的模型。由于其紧凑的内部表示和减少了特征冗余,DenseNet可能是建立在卷积特征上的各种计算机视觉任务的良好特征提取器,例如39 40。我们计划在未来的工作中使用DenseNets研究这种特征的转移。
致谢:作者得到国家科学基金会资助的项目III-1618134,III-1526012,IIS-1149882,海军研究所资助的项目N00014-17-1-2175以及比尔和梅琳达·盖茨基金会的支持。Gao Huang得到中国博士后国际博士后科学研究项目(No.20150015)支持。 Zhuang Liu得到中国国家基础研究计划资助的项目2011CBA00300,2011CBA00301,中国国家自然科学基金资助的项目61361136003。我们还感谢Daniel Sedra,Geoff Pleiss和Yu Sun和我们进行了许多有见地的讨论。
参考文献:
-
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4):541–551, 1989. ↩
-
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. ↩ ↩2
-
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV. ↩ ↩2
-
R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. In NIPS, 2015. ↩ ↩2 ↩3 ↩4
-
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10
-
G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger. Deep networks with stochastic depth. In ECCV, 2016. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
G. Larsson, M. Maire, and G. Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. arXiv preprint arXiv:1605.07648, 2016. ↩ ↩2 ↩3 ↩4
-
Q. Liao and T. Poggio. Bridging the gaps between residual learning, recurrent neural networks and visual cortex. arXiv preprint arXiv:1604.03640, 2016. ↩
-
C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeply-supervised nets. In AISTATS, 2015. ↩ ↩2 ↩3 ↩4 ↩5
-
S. E. Fahlman and C. Lebiere. The cascade-correlation learning architecture. In NIPS, 1989. ↩
-
B. M. Wilamowski and H. Yu. Neural network learning without backpropagation. IEEE Transactions on Neural Networks, 21(11):1793–1803, 2010. ↩
-
B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. In CVPR, 2015. ↩
-
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. ↩
-
P. Sermanet, K. Kavukcuoglu, S. Chintala, and Y. LeCun. Pedestrian detection with unsupervised multi-stage feature learning. In CVPR, 2013. ↩
-
S. Yang and D. Ramanan. Multi-scale recognition with dagcnns. In ICCV, 2015. ↩
-
C. Cortes, X. Gonzalvo, V. Kuznetsov, M. Mohri, and S. Yang. Adanet: Adaptive structural learning of artificial neural networks. arXiv preprint arXiv:1607.01097, 2016. ↩
-
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015. ↩ ↩2
-
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016. ↩ ↩2 ↩3
-
S. Targ, D. Almeida, and K. Lyman. Resnet in resnet: Generalizing residual architectures. arXiv preprint arXiv:1603.08029, 2016. ↩
-
S. Zagoruyko and N. Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016. ↩ ↩2 ↩3
-
M. Lin, Q. Chen, and S. Yan. Network in network. In ICLR, 2014. ↩ ↩2 ↩3
-
A. Rasmus, M. Berglund, M. Honkala, H. Valpola, and T. Raiko. Semi-supervised learning with ladder networks. In NIPS, 2015. ↩
-
M. Pezeshki, L. Fan, P. Brakel, A. Courville, and Y. Bengio. Deconstructing the ladder network architecture. In ICML, 2016. ↩
-
J. Wang, Z. Wei, T. Zhang, and W. Zeng. Deeply-fused nets. arXiv preprint arXiv:1605.07716, 2016. ↩
-
Y. Zhang, K. Lee, and H. Lee. Augmenting supervised neural networks with unsupervised objectives for large-scale image classification. In ICML, 2016. ↩
-
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. ↩ ↩2
-
X. Glorot, A. Bordes, and Y. Bengio. Deep sparse rectifier neural networks. In AISTATS, 2011. ↩ ↩2
-
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio. Fitnets: Hints for thin deep nets. In ICLR, 2015. ↩
-
J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806, 2014. ↩
-
I. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio. Maxout networks. In ICML, 2013. ↩
-
P. Sermanet, S. Chintala, and Y. LeCun. Convolutional neural networks applied to house numbers digit classification. In ICPR, pages 3288–3291. IEEE, 2012. ↩
-
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. ↩
-
S. Gross and M. Wilber. Training and investigating residual nets, 2016. ↩ ↩2 ↩3
-
I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. In ICML, 2013. ↩
-
K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015. ↩
-
N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. JMLR, 2014. ↩
-
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. ↩
-
J. R. Gardner, M. J. Kusner, Y. Li, P. Upchurch, K. Q. Weinberger, and J. E. Hopcroft. Deep manifold traversal: Changing labels with convolutional features. arXiv preprint arXiv:1511.06421, 2015. ↩
-
L. Gatys, A. Ecker, and M. Bethge. A neural algorithm of artistic style. Nature Communications, 2015. ↩