摘要
DenseNet架构1由于特征重用而具有很高的计算效率。然而,原始的DenseNet实现可能需要大量的GPU内存:如果不处理得当,预激活批量归一化2和连续卷积操作可以生成随网络深度的平方增长的特征图。在本中中,我们介绍了减少训练过程中DenseNet的内存消耗的策略。通过策略性地使用共享内存分配,我们将存储特征图的内存成本从深度的平方减少到随深度线性增长。没有GPU内存的瓶颈,现在可以训练极深的DenseNet。具有14M个参数的网络可以在单个GPU上训练,提高了4M。以前不可能训练的264层DenseNet(73M个参数)现在可以在一台具有8个NVIDIA Tesla M40 GPU的工作站上进行训练。在ImageNet ILSVRC分类数据集上这个大型的DenseNet达到了20.26%的领先的single-crop top-1错误率。
简介
DenseNet架构1在参数使用和计算时间方面都非常高效。在ImageNet ILSVRC-2012数据集[13]中,201层DenseNet达到了与101层残差网络(ResNet)3大致相同的top-1个分类错误,却仅使用一半参数(20M vs 44M)和一半的浮点运算(80B/图像 vs 155B/图像)。每个DenseNet层都明确地连接到密集块内的所有以前的层,而不是仅接收最近层的信息。这些连接促进特征重用,因为所有其它层可以利用先前层的特征。由于特征积累,最终分类层可以访问大量且多样化的特征表示。
这种固有的效率使DenseNet架构成为高容量网络的首选。 Huang等人1报告说,161层DenseNet(每层$k = 48$个特征和29M参数)在ImageNet ILSVRC分类数据集上的single-crop top-1错误为22.2%。更深层的网络应该可以达到更好的效果。然而,对于大多数现有的DenseNet实现,模型大小目前受GPU内存限制。
每层只产生$k$个特征图(其中$k$很小 - 通常在12和48之间),但是由于使用所有以前的特征图作为输入。这导致参数的数量随网络深度的平方增长。值得注意的是,参数数量与深度之间的平方关系并不是一个缺陷,因为具有更多参数的网络表现更好,在这方面,DenseNets比其它架构更具竞争力,如,ResNet。然而,DenseNets的大多数原始实现中,特征图的内存占用和深度也是平方关系,绝大多数内存消耗都来源于此。正如我们在本文中所说的那样,这是实现问题,而不是DenseNet体系结构的固有问题。
特征图的内存占用问题源自每层生成的中间特征图,这是批量归一化和特征图串联操作的输出。在向前传递(计算下一个特征)和反向传播(计算梯度)期间都使用中间特征图。如果不处理得当,内存效率会比较低。
在文中,我们引入了大幅降低DenseNet在训练时内存消耗的实现策略,训练速度略有降低。我们的主要观点是,消耗大部分内存的中间特征图相对易于计算。这允许我们引入共享内存分配,这些内存由所有层使用以存储中间结果。后续层覆盖先前层的中间结果,但是可以以很小的代价在反向传播过程中重新计算它们的值。这样做将特征图内存消耗从二次方减少到线性,同时只增加了15-20%的额外训练时间。这种内存的节省使得可以在合理的GPU预算上训练极大的DenseNet。特别是,我们能够将最大的DenseNet从161层(每层$k = 48$个特征,20M参数)扩展到264层($k = 48$,73M参数)。在ImageNet上,该模型达到了20.26%的single-crop top-1错误率,据我们所知,这是最好的结果。
我们的节约内存策略在现有的深入学习框架中实现起来比较简单。我们提供了多种实现:
-
Torch(https://github.com/liuzhuang13/DenseNet/tree/master/models)4
-
PyTorch(https://github.com/gpleiss/efficient_densenet_pytorch)5
-
MxNet(https://github.com/taineleau/efficient_densenet_mxnet)6
-
Caffe(https://github.com/Tongcheng/DN_CaffeScript)7
DenseNet架构
总体上来看,DenseNet明确地连接所有特征尺寸匹配的层。 如下图(图1)所示:
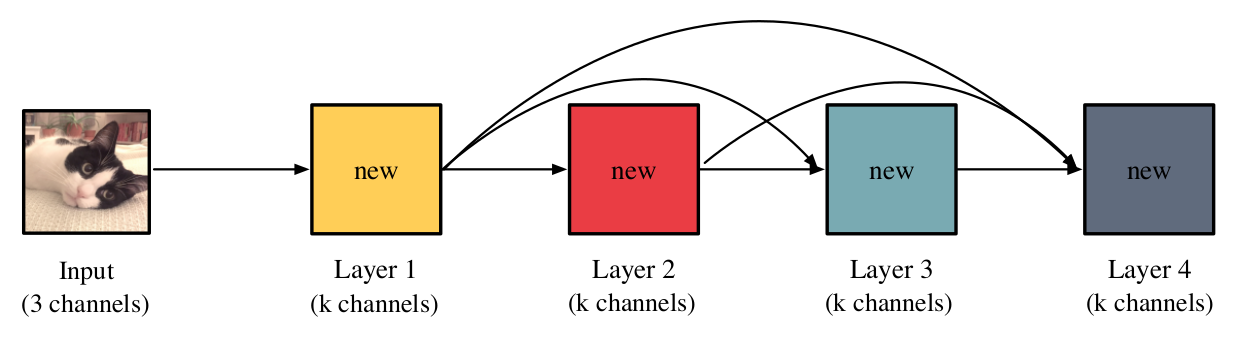
黄等人将一组直接连接的层称为密集块,通常在其后面是池化层(减少特征图尺寸)或最终分类器。传统神经网络层仅使用最新的特征。在DenseNet中,层可以访问其密集块中的所有先前层的特征。用公式来表示:($x_{\ell}$表示层$\ell$生成的特征) \(x_{\ell} = H_{\ell}([x_{1},...,x_{\ell -1}])\) 其中$H_{\ell}$表示层$\ell$的操作,$[\cdot]$表示串联操作。 黄等人1将$H_{\ell}$定义为三个操作的组合:依次是批量归一化8,线性整流单元(ReLU)和卷积。 ($H_{\ell}$也可能包括额外的操作,如“瓶颈层”1。)在大多数深入的学习框架中,这三个操作中的每个都产生中间特征图。
给定m层的密集块,其最终层的输入为$[x_{1},…,x_{m -1}]$,即所有先前层的卷积特征。由于卷积特征的数量随网络深度呈线性增长,因此将它们存储在内存中不会产生显著的内存负担。然而,如果网络也存储中间特征图(例如,批量归一化输出),GPU内存可能变成有瓶颈。由于为每层都计算了中间特征,因此如果它们被存储则产生了$O(m^2)$的内存使用。许多深度学习框架将这些中间特征图保留在GPU内存中,以便在反向传播过程中使用。卷积特征(和参数)的梯度通常是中间输出的函数,因此中间输出必须保持可访问以用于反向传播。在DenseNet中,有两个操作导致了$O(m^2)$的内存使用:预激活批量归一化和串联。
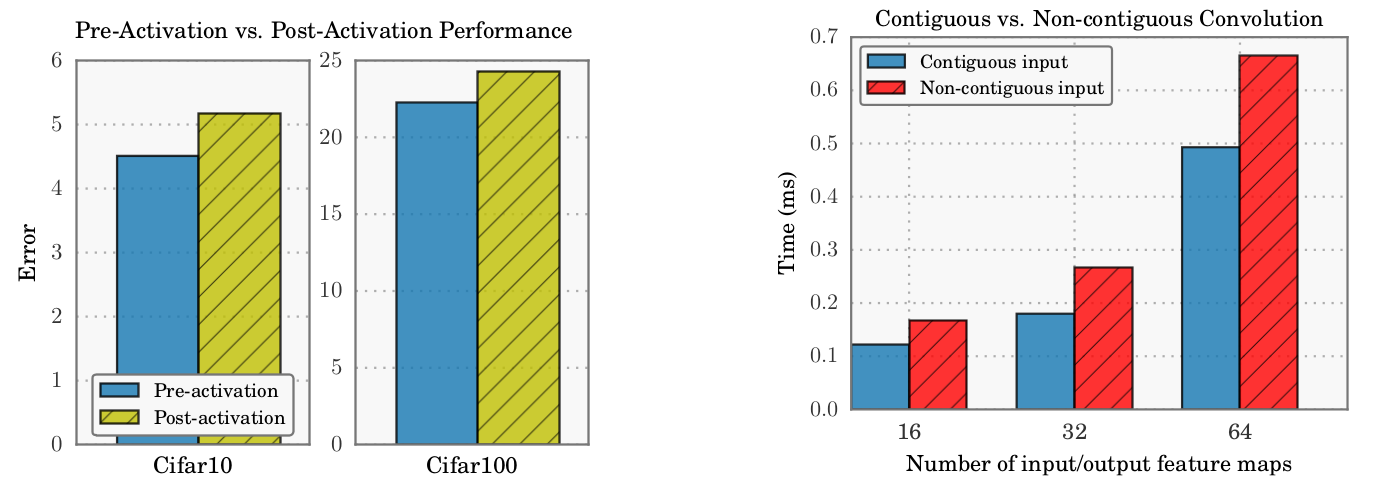
预激活批量归一化。如1所述,DenseNet架构使用预激活批量归一化2。与传统架构不同,预激活网络在卷积运算之前而不是之后应用批量归一化和非线性。虽然这似乎是一个小小的变化,但它在DenseNet性能上有很大的不同。批量归一化对输入特征应用缩放和偏置。如果每个层都应用自己的批量归一化操作,那么每个层对先前的特征应用唯一的缩放和偏差。例如,第2层批量归一化可能会对第1层的特征用正数进行缩放,而第3层可能会将相同的特征用负数缩放。在应用非线性之后,层2和层3从层1提取相反的信息。如果所有层共享相同的批量归一化操作,或者在卷积操作之后发生归一化,就不会发生这种情况。如果没有预激活,100层DenseNet-BC($k = 12$)的CIFAR-10上的错误从4.51增长到5.18。在CIFAR-100上,错误从22.27增加到24.30。如下图(图2左侧)所示:
给定一个具有m层的DenseNet,预激活可以产生高达每层m个归一化副本。由于每个副本具有不同的缩放和偏置,因此在标准深度学习框架上的原始实现通常为这$(m - 1)(m - 2) / 2$重复的特征图分别分配内存。
串联。当所有输入数据位于连续的内存块中时,卷积运算速度最快。一些深度学习框架,如Torch,明确要求所有卷积操作在连续内存上执行。虽然CUDNN是最常见的底层卷积运算库9,却没有这个要求。使用不连续的内存块会增加30-50%的计算时间开销(图2右图)。
为了建立连续的输入,每个层必须将所有先前的特征复制到连续的内存块中。给定具有$m$层的网络,每个特征可被最多复制$m$次。如果这些副本分开存储,则串联操作也将产生$O(m^2)$的内存开销。
值得注意的是,我们不能简单地将卷积输出分配给预先分配的连续的内存块。特征被表示为$\mathbb{R}^{n \times d \times w \times h}$(或$\mathbb{R}^{n \times w \times h \times d}$)大小的张量,其中$n$是小批量样本的数量,$d$是特征图的数量,$w$和$h$是宽度和高度。 GPU卷积运算(如CUDNN)假设小批量是最低维度,即,连续的内存中存储的是小批量内不同张量中相同坐标的值(GPU计算单元中一组PE的访存优化,可参考GPU架构相关文档),而不是我们预期的特征图排列顺序。
原始实现
在现代深度学习库中,计算操作通常由计算图中的边表示。计算图节点表示存储在存储器中的中间特征图。
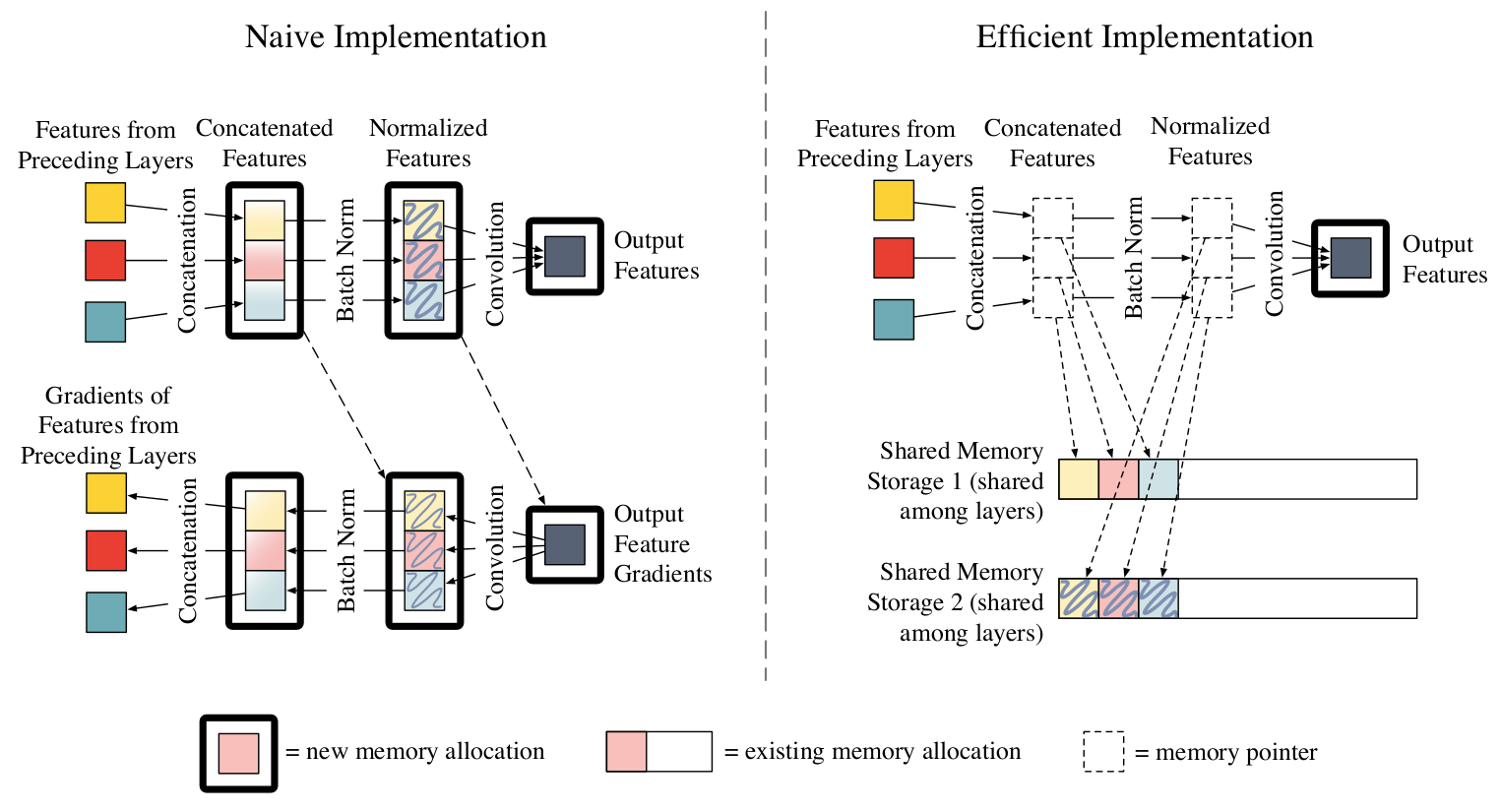
DenseNet层的原始实现(无瓶颈层)的计算图如上图(图3左上)所示。(计算图大致基于原始实现:https://github.com/liuzhuang13/DenseNets/)每层的输入是先前层的特征(彩色框)。由于这些特征源于不同的层,它们不会连续存储在内存中。因此,原始实现的第一操作是复制这些特征中的每一个并将它们连接到连续的存储块(左中)。如果$\ell$个先前层每个生成$k$个特征,则连续的内存块必须容纳$\ell \times k$个特征图。这些连接的特征被输入到批量归一化操作中(中心右),其类似地分配新的$\ell \times k$个连续的存储块。(ReLU不分配新的内存,而是直接在现有内存上计算,因此为了简化,我们选择将其从计算图中排除。)最后,卷积运算(最右)从批量归一化输出生成$k$个新特征。从图3(左上角)可以清楚地看出内存的平方增长。两个中间操作需要一个$O(\ell k)$大小的内存来存储先前层计算的特征。相比之下,输出特征只需要每层一个恒定$O(k)$大小的内存。
在一些深度学习框架中,例如LuaTorch,在反向传播过程中可能会分配更多的内存。图3(左下)显示梯度的计算图。使用输出特征梯度(最右)和从正向(虚线)的归一化特征图计算批量归一化梯度(中心右)。存储这些梯度需要额外的$\ell \times k$个特征图大小的内存分配。类似地,也需要$\ell \times k$个特征图大小的内存来存储串联的特征梯度。
节约内存的实现
我们利用串联和归一化操作在计算上较小这一特点来规避内存的问题。我们使用两个预分配的共享内存池来减小内存的开销。在正向传播时,我们将所有中间输出存储在这些内存块。在反向传播过程中,我们会根据需要重新计算串联和归一化的特征。
这个重新计算策略已经被其它神经网络架构使用。陈等10利用重新计算在单个GPU上训练1000层ResNet。另外,Chen等6已经在MxNet深度学习框架中为任意网络开发了重新计算支持。一般来说,重新计算中间输出需要权衡时间换空间是否值得。我们发现这种策略对于DenseNets非常实用。串联和批量归一化操作使用了大多数的内存,但只占总计算时间的一小部分。因此,重新计算这些中间输出可以节省大量的内存,而且计算时间开销很小。
(后面的是Google翻译的,就不人工翻译了,绕来绕去都是那几句,时间换空间)
用于连接的共享存储。第一个操作 - 特征级联 - 需要O(k)存储器存储,其中是先前层的数量,k是每层添加的功能数量。不是为每个级联操作分配内存,而是将输出分配给跨所有层共享的内存分配(图3中的“共享内存存储1”)。因此,级联特征图(中心左)是指向该共享存储器的指针。复制到预先分配的内存明显快于分配新内存,因此这种连接操作非常有效。将这些连接特征作为输入的批量归一化操作直接从共享存储器存储器1读取。由于所有网络层使用共享存储器1,所以它的数据不是永久的。当在反向传播期间需要连接的特征时,我们假设可以有效地重新计算它们。
用于批量归一化的共享存储。类似地,我们将批量归一化(其也需要O(m)存储器)的输出分配给共享存储器分配(“共享存储器存储2”)。卷积操作从指向该共享存储的指针(中间右侧)读取。与连接一样,在反向传播期间,必须重新计算批量归一化输出,因为共享内存存储2中的数据不是永久性的,将被下一层覆盖。然而,批量归一化包括标量乘法和加法运算,与卷积数学相比非常有效。计算批量归一化特征约占前向后向合格的5%,因此重复操作不是昂贵的操作。
梯度共享存储。串联,批量归一化和卷积运算在反向传播过程中都产生梯度张量。在LuaTorch中,直接确保这个张量数据存储在单个共享内存分配中。这种策略可以防止渐变存储二次增长。我们使用基于Facebook ResNet实现的内存共享方案。 (https://github.com/facebook/fb.resnet.torch) PyTorch和MxNet框架共享渐变存储开箱即用。
将这些组合放在一起,前向传递(图3右侧)与本机实现类似(图3左上角),但中间特征映射存储在共享内存存储1或共享内存存储2中。后向传递需要一个额外的步骤:我们首先重新计算连接和批处理规范化操作(中心左和右中),以便使用适当的功能图数据重新填充共享内存存储。一旦共享存储器存储包含正确的数据,我们可以执行常规的反向传播来计算梯度。总而言之,DenseNet实现只为输出特征(最右边)分配内存,这些大小是不变的。其功能图的整体内存消耗在网络深度方面是线性的。
效果
我们比较三种DenseNet实现在训练过程中的内存消耗和计算时间。本地实现基于Huang等人的原始LuaTorch实现(https://github.com/liuzhuang13/DenseNet)。 [9]。如第3节所述,此实现为连接和批量归一化输出分配内存。另外,这些操作中的每一个使用附加存储器来存储中间特征的梯度。因此,该实现具有四次具有二次内存增长的操作(两个前向操作和两个反向传递操作)。
然后,我们测试DenseNets的两个高效的内存实现。第一个实现共享梯度存储,使得在反向传播期间没有新的内存分配。所有渐变都被分配给共享内存存储。 LuaTorch渐变存储器共享代码基于Facebook的ResNet实现(https://github.com/facebook/fb.resnet.torch)。 PyTorch自动执行此优化开箱即用。第二个实现包括第4节中描述的所有优化:用于批量归一化,连接和渐变操作(共享梯度+ B.N. + concat存储)的共享存储。在反向传播期间,根据需要重新计算级联和归一化的特征图。培训期间存储在存储器中的唯一张量是卷积特征图和网络参数。
这三个实现的内存消耗(在LuaTorch和PyTorch中)如下图(图4)所示:
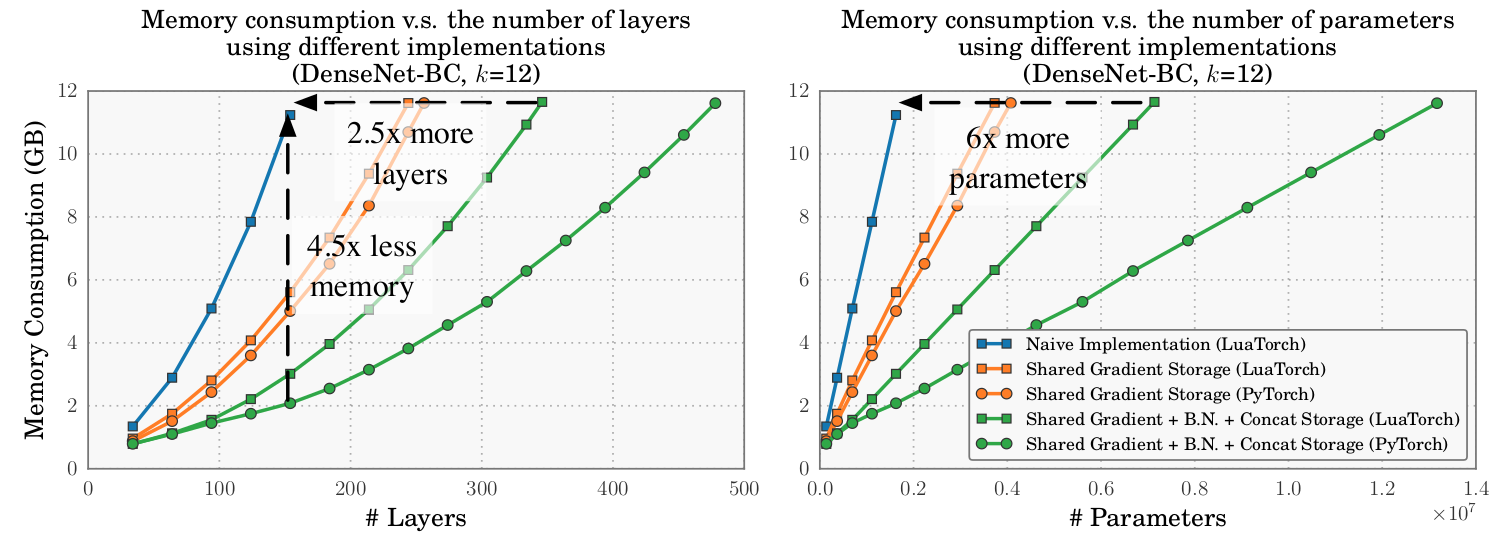
(没有PyTorch本机实现,因为PyTorch自动共享渐变存储。)通过四次二次运算,本地实现非常快速地成为内存密集型。 160层网络的存储器使用量(每层k = 12个特性,1.8M参数)大约是40层网络的10倍(k = 12,160K参数)。培训超过160层的大型网络需要超过12 GB的内存,这不仅仅是典型的单GPU。共享梯度降低了内存成本的一部分,内存消耗仍随着深度而快速增长。另一方面,使用所有的内存共享操作显着地减少了内存消耗。在LuaTorch中,160层模型使用Native Native所需的22%的内存。在相同的内存预算(12 GB)下,可以训练一个340层的模型,它是2.5x深的,具有最好的本地实现模型的6倍的参数。
值得注意的是,最有效的实现的总体内存消耗不会随深度线性增长,因为参数的数量本质上是网络深度的二次函数。这是建筑设计的一个功能,也是DenseNets如此高效的一部分原因。存储参数所需的内存远小于特征图所消耗的内存,剩余的二次项不会妨碍模型的深度。
最后,我们在图4中看到,PyTorch比LuaTorch具有更高的内存效率。使用有效的PyTorch实现,我们可以在单个GPU上训练近500层(13M参数)的DenseNets。 PyTorch的“Autograd”库在培训过程中执行内存优化,这可能有助于实现这一实现的效率。
内存优化不会对训练时间产生显着的影响。如下图(图5)所示:
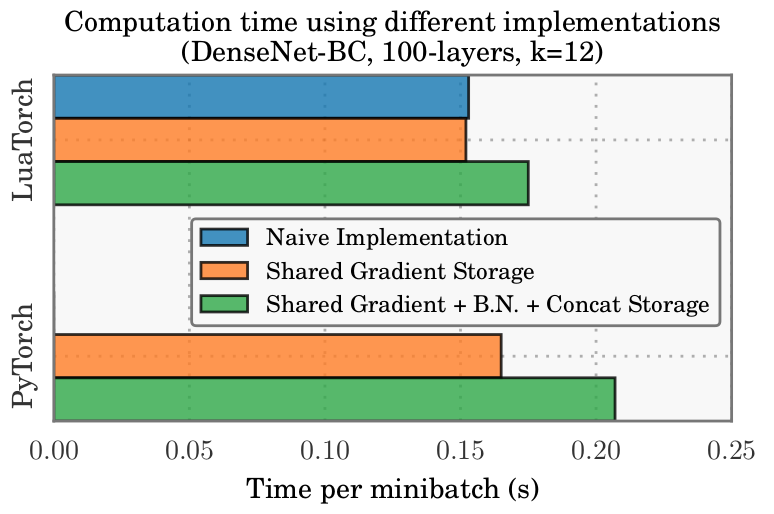
我们绘制了一个100层DenseNet-BC(k = 12)在NVIDIA Maxwell Titan-X上的每个分段的时间。共享梯度存储不会产生任何时间成本。共享批量归一化和级联存储在LuaTorch上增加了大约15%的时间开销,在PyTorch上增加了20%。这种额外的成本是反向传播期间重新计算操作的结果。对于任何大小的DenseNets,共享渐变存储是有意义的。如果GPU内存有限,共享批量归一化/级联存储的时间开销构成合理的权衡。
ImageNet结果。我们在ImageNet IVLSRC分类数据集[13]上测试新的内存高效的LuaTorch实现(用于梯度的共享内存存储,批量归一化和级联)。由Huang等人训练的最深刻的模式[9]使用原始的LuaTorch实现是161层(每层k = 48个特征,29M参数)。然而,通过高效的LuaTorch实现,可以使用8个NVIDIA Tesla M40 GPU来训练264层DenseNet(k = 48,73M参数)。
我们训练两个新的DenseNet模型,其高效实现,一个264层(k = 32,33M参数),一个具有232层(k = 48,55M参数)。 (这个模型有四个密集块。在264层模型中,密集块分别具有6,32,64和48层。在232层模型中,密集块具有6,32,48和48层。)这些模型按照[9]中描述的相同过程训练了100个历元。另外,我们训练两个DenseNets模型,它们具有余弦学习速率表(DenseNet cosine),类似于[12]和[8]中使用的。该模型训练了100个时期,时期的学习率设置为0.05 cos(t(pi / 100))+ 1。直观地,该学习速率计划以很大的学习速率开始,并且快速(但顺利)将学习率降至一个小的价值。两个余弦DenseNets有264层 - 一个具有k = 32(33M参数),一个具有k = 48(73M参数)。给定了一个固定的GPU预算,这些DenseNet模型只能通过有效的实现进行培训。
如下图(图6)所示:
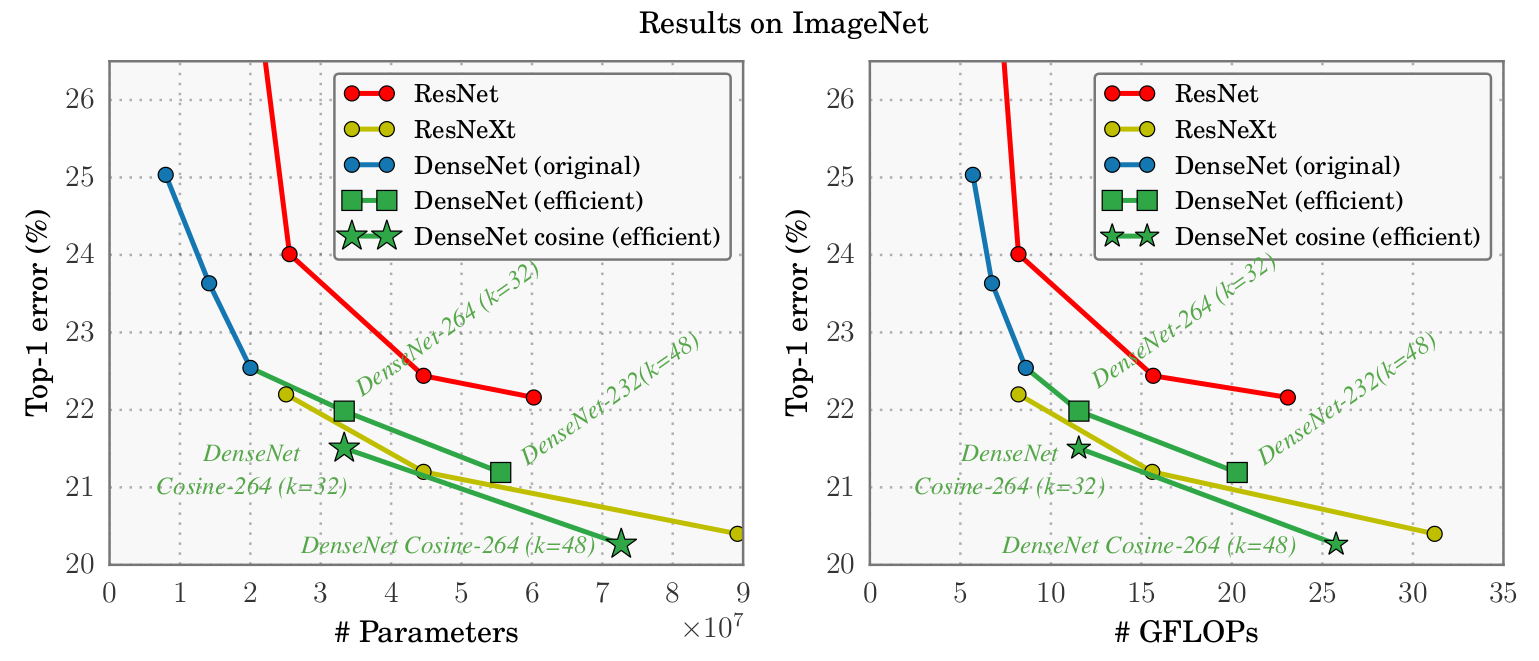
这些DenseNets的前1个错误性能。用有效实现训练的模型被表示为绿色点(标准学习速率表的平方,余弦星)。我们将这些模型的性能与使用原始实施训练的浅层DenseNets进行比较。另外,我们比较[6]中引入的ResNet模型和[14]中介绍的ResNeXt模型。用单中心试验作物获得结果。
新的DenseNet型号(标准培训程序)比最深的ResNet模型实现了比1%更好的误差,同时使用较少的参数。此外,最深的余弦DenseNet实现了20.26%的前1个错误,超过了以前的最先进的模型[14]。从这些结果可以看出,随着添加更多的层数,DenseNet性能可以持续改进。
结论
在本文中,我们描述了DenseNet新的实现策略。以前的DenseNet实现在训练过程中存储所有中间特征图,导致特征图内存使用量随着深度的平方增长。通过采用共享内存缓冲区并重新计算一些开销较小的转换,只增加了很少的计算时间,就使模型使用的内存显著减少。有了这个新的实现策略,内存不再是训练非常深的DenseNet的瓶颈。因此,我们可以将先前模型的深度加倍,从而可以显著降低ImageNet数据集上的top-1错误。
致谢:作者得到国家科学基金会资助的项目III-1618134,III-1526012,IIS-1149882,海军研究所资助的项目N00014-17-1-2175以及比尔和梅琳达·盖茨基金会的支持。
参考文献:
-
G. Huang, Z. Liu, K. Q. Weinberger, and L. van der Maaten. Densely connected convolutional networks. In CVPR, 2017. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016. ↩ ↩2
-
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016. ↩
-
R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, 2011. ↩
-
Pytorch. https://github.com/pytorch. Accessed: 2017-06-09. ↩
-
T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv preprint arXiv:1512.01274, 2015. ↩ ↩2
-
Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093, 2014. ↩
-
S. Ioffe and C. Szegedy. batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. ↩
-
S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer. cudnn: Efficient primitives for deep learning. arXiv preprint arXiv:1410.0759, 2014. ↩
-
T. Chen, B. Xu, C. Zhang, and C. Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016. ↩